
Table of Contents
什么是链路追踪?
链路追踪顾名思义就是在一个系统里,从请求开始到请求结束,记录这个请求过程的东西。当然这个记录的粒度按需设定,可以是服务级别,也可以是方法级别,
这个粒度就是下面将要介绍的OpenTracing里的span概念, 整个trace就是由多个span组成了一个有向无环图(DAG)。
像这样:
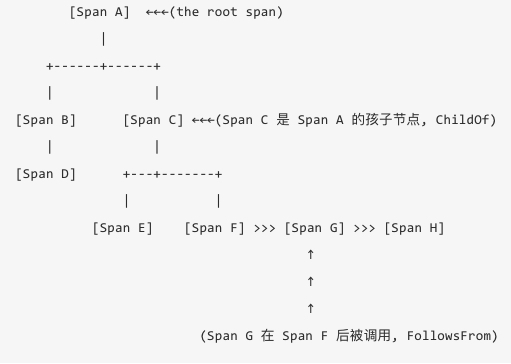 span DAG
span DAG
什么是OpenTracing?
OpenTracing是CNCF(云原生计算基金会)对链路追踪做的一个规范。因为数据采集的过程中往往会对代码进行入侵式埋点,然而不同的链路追踪的系统API各不相同,如果后期希望切换就会带来很大的改动, 为了解决这种不兼容的问题,OpenTracing孕育而生。大家都依据这个规范去实现,使用者可以不用去关心背后采用的追踪引擎是什么。
简单的说就是OpenTracing提供平台无关,厂商无关的API,是开发者能够方便自如的添加更换追踪系统的实现。
语义概念
span
一个span代表系统中具有开始时间和执行时长的逻辑运行单元,span之间通过嵌套或者顺序建立逻辑关系。
如果把整个trace的有向无环图按时间轴展开,那么span和trace的关系图如下:
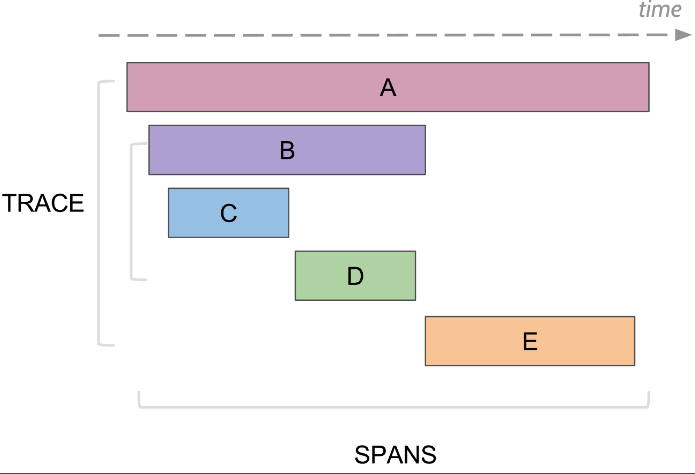 span trace relation
span trace relation
从时间轴上可以看到,A覆盖了所有下面子条目的时间,这很容易理解:所有的Span组成一个Trace,而每个Span实际上都消耗了时间,除去重叠部分这些时间的总合就是Trace的时间消耗
Span有父子级别概念:B和C以及D的关系就是父子,而C和D则不是父子关系,父子的时间是重合的,就类似所有子Span和Trace之间的时间关系,B消耗的时间是C和D的时间总合,而A消耗的时间则是B和E的总合
图中:
1. 在Trace A中,B和E是A的子Span
2. 在Trace A中,B和E是A的子Span
3. 在Trace A中,B和E顺序执行,E的执行需要等待B的完成
4. A的消耗时长为B和E的总合(这里都是理想情况)
5. 在Span B中,C和D是B的子Span
6. 在Span B中,C和D顺序执行,D的执行需要等待C的完成
7. B的消耗时长为C和D的总合(这里都是理想情况)
根据OpenTracing的规范,一个span封装了以下信息:
- An operation name 操作名称
- A Start timestamp 起始时间
- A finish timestamp 结束时间
- Span Tag 一组键值对,key必须是
string类型,值可以是string,bool,number类型 - Span Log 一组日志集合,每个log操作包含一个键值对
- A SpanContext span的上下文
Span Context span的上下文
spanContext 可以承载数据跨进程进行传输。
Reference span之间的关系
一个span可以和一个或者多个span间存在逻辑因果关系。OpenTracing里定义了两种关系:ChildOf 和 FollowFrom。
ChildOf : 一个span归属于另一个span,即ChildOf关系。 下面几种情况会构成这种关系:
- 一个RPC调用的服务端的span和RPC服务客户端的span
- 一个sql insert操作的span, 和ORM的save方法的span
- 很多span可以并行工作(或者分布式工作)都可能是一个父级的span的子项,他会合并所有子span的执行结果,并在指定期限内返回
FollowFrom : 用于span独立于父span,比如异步的情况下。
Baggage
Baggage Items trace的随行数据,是一个键值对集合,可以在不改动原有header的情况下传递数据
Inject/Extract
为了在分布式系统里进行跨进程追踪,服务需要能够延续跟踪从客户端发过来的请求。OpenTracing 提供了inject和extract两个方法,先把spanContext序列化后放入一个载体(这个载体可能是http header),发送到下游后再进行反序列化读取上游trace信息。
流程如下图:
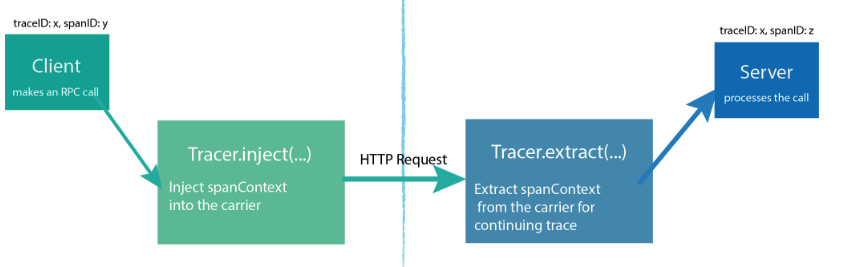 inject & extract
inject & extract
Jaeger架构
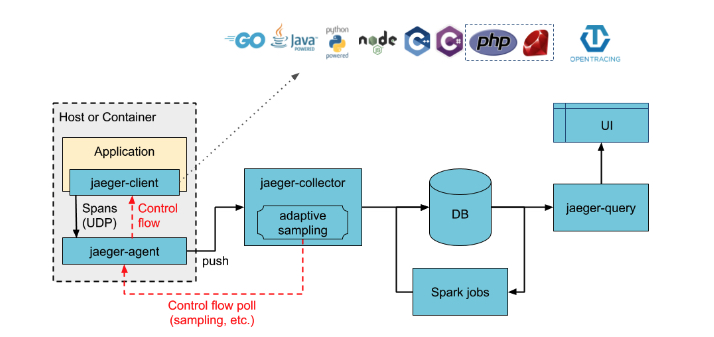 inject & extract
inject & extract
从上面的图中可以看出这个架构一共分为五个大部分。分别是:
- Jaeger Client
- Jaeger Agent
- Jaeger Collector
- Data Store
- Jaeger Query/Jaeger-UI
Jaeger Client
这个client就是基于OpenTracing API协议的多语言实现。这部分就是你的代码里的一个类库文件,是你应用程序的一部分,埋点操作就是在这个部分。
应用程序通过API写入数据,把trace信息按照应用程序指定的采样策略传递给jaeger-agent
Agent
Agent是一个Client并行部署的一个组件,是一个长期启动的守护进程,通过监听UDP接收Client发送过来的Trace信息,并批量发送到Collector.
Agent存在的目的就是解耦Client和Collector,为client屏蔽了路由和发现collector的细节。
Collector
Collector是Jaeger的核心,接收从Agent发送过来的Trace信息,并对其进行验证,索引,转换并且最终存储起来。
Data Store
Jaeger 的数据存储是可插拔式组件设计,有多种存储可选:Cassandra, Elasticsearch, Kafka(只能当做临时buffer,不能当最终存储)。
但是官方推荐Canssandra,因为新特性更新和稳定性都是最好的。
Query
接受到查询请求,从后端存储中检索trace并通过UI进行展示。Query是无状态的,可以启动多个实例。
Context 传播
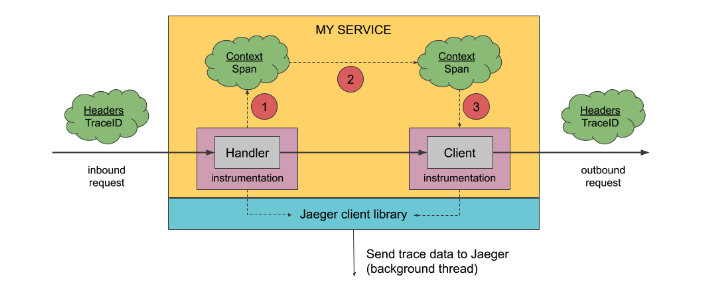 inject & extract
inject & extract
Jaeger配置项说明
采样
链路追踪是一个频繁而且数据量庞大的工作,所以提供了依据不同的业务场景,提供不同的采样策略,来减轻数据压力。
Constant: 常量策略
| 类型 | sampler.type=const |
|---|---|
| 值 | sampler.param=1:全部采样 sampler.param=0:全部丢弃 |
Probabilistic: 概率决策
| 类型 | sampler.type=probabilistic |
|---|---|
| 值 | sampler.param=0.1:表示采样1/10 |
Rate Limiting: 频次策略
| 类型 | sampler.type=ratelimiting |
|---|---|
| 值 | sampler.param=2.0:表示每秒采样2次 |
Remote 远端决策
| 类型 | sampler.type=remote |
|---|
这种情况就是Client发送到Agent,Agent来进行采样决策,实际上配置是在Collector上。
介绍就到这,接下来下面更新Opentracing的实际操作。
